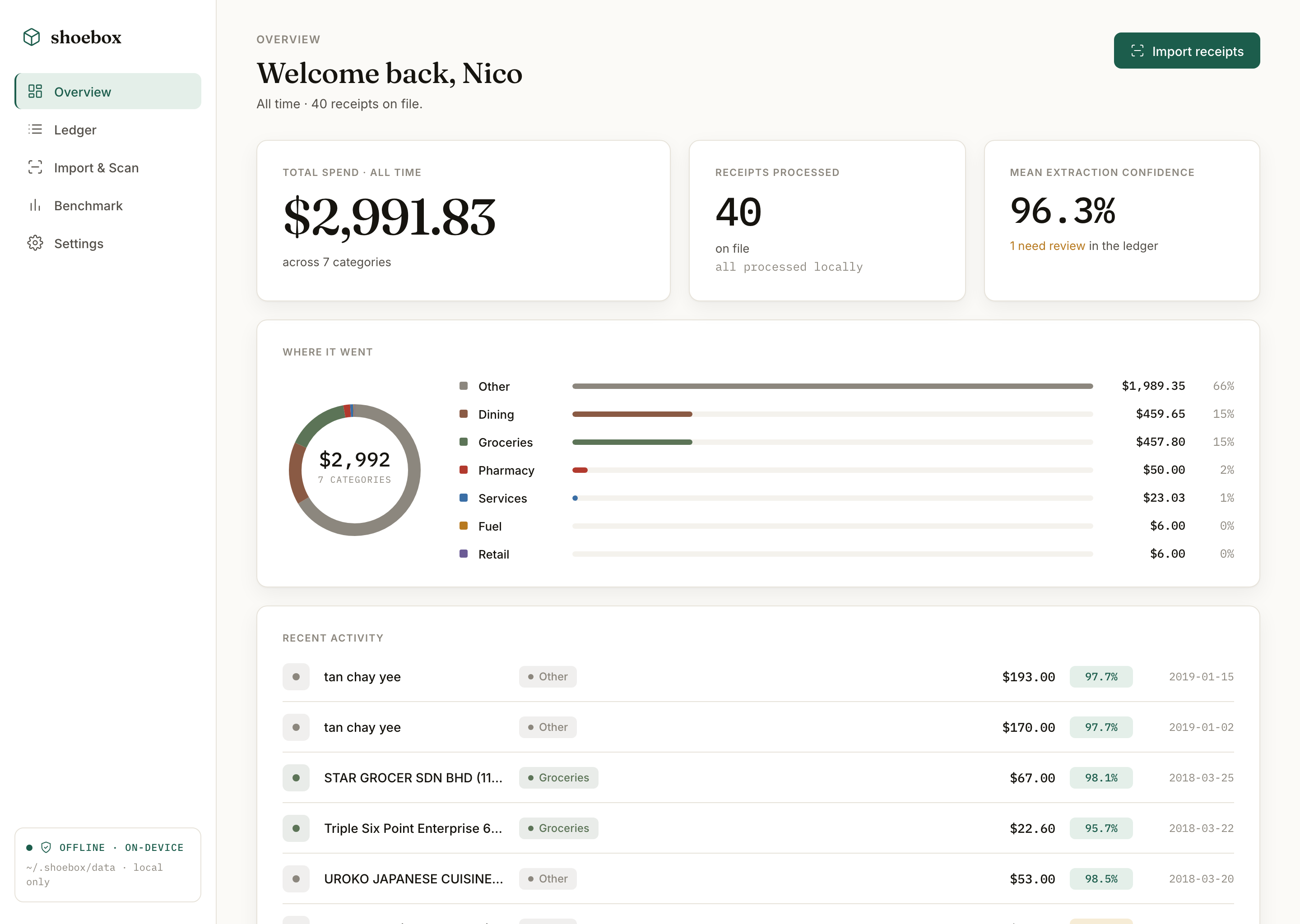
shoebox: On-device receipt OCR at 90% of cloud, for $0
A privacy-first receipt digitizer that never leaves your laptop. Local OCR plus a quantized LLM reach ~90% of frontier cloud-vision accuracy on field extraction, offline and at zero cost, benchmarked head-to-head.
TL;DR
- A fully on-device receipt digitizer (no image ever leaves the laptop), benchmarked head-to-head against frontier cloud vision.
- Local stack (PaddleOCR + Qwen-3B q8) hits 74.0% field-level accuracy vs 82.7% for cloud (Groq Llama-4-Scout): ~90% of the frontier, at $0 and fully offline.
- A QLoRA fine-tune (MLX) lifts the local model from 72% → 80% on SROIE, published to the HF Hub.
Problem
Privacy is the product, not a setting.
shoebox is the deliberate counter-narrative to a cloud bill-reader: same document domain, opposite deployment philosophy. Receipts are some of the most personal data you own: where you were, what you bought, when. The question I wanted to answer with numbers, not vibes: how much accuracy do you actually give up to keep all of it on your own machine?
Architecture
receipt photo → OpenCV preprocess (crop · deskew) → PaddleOCR → local LLM extract → CSV ledger
↑ swappable Extractor (Ollama · Gemini · Groq)
Every stage is a pure-ish module speaking one typed pydantic contract. Raw OpenCV/PaddleOCR output is parsed into a model at the boundary, and nothing untyped escapes it.
Key decisions
A measured benchmark over a privacy claim
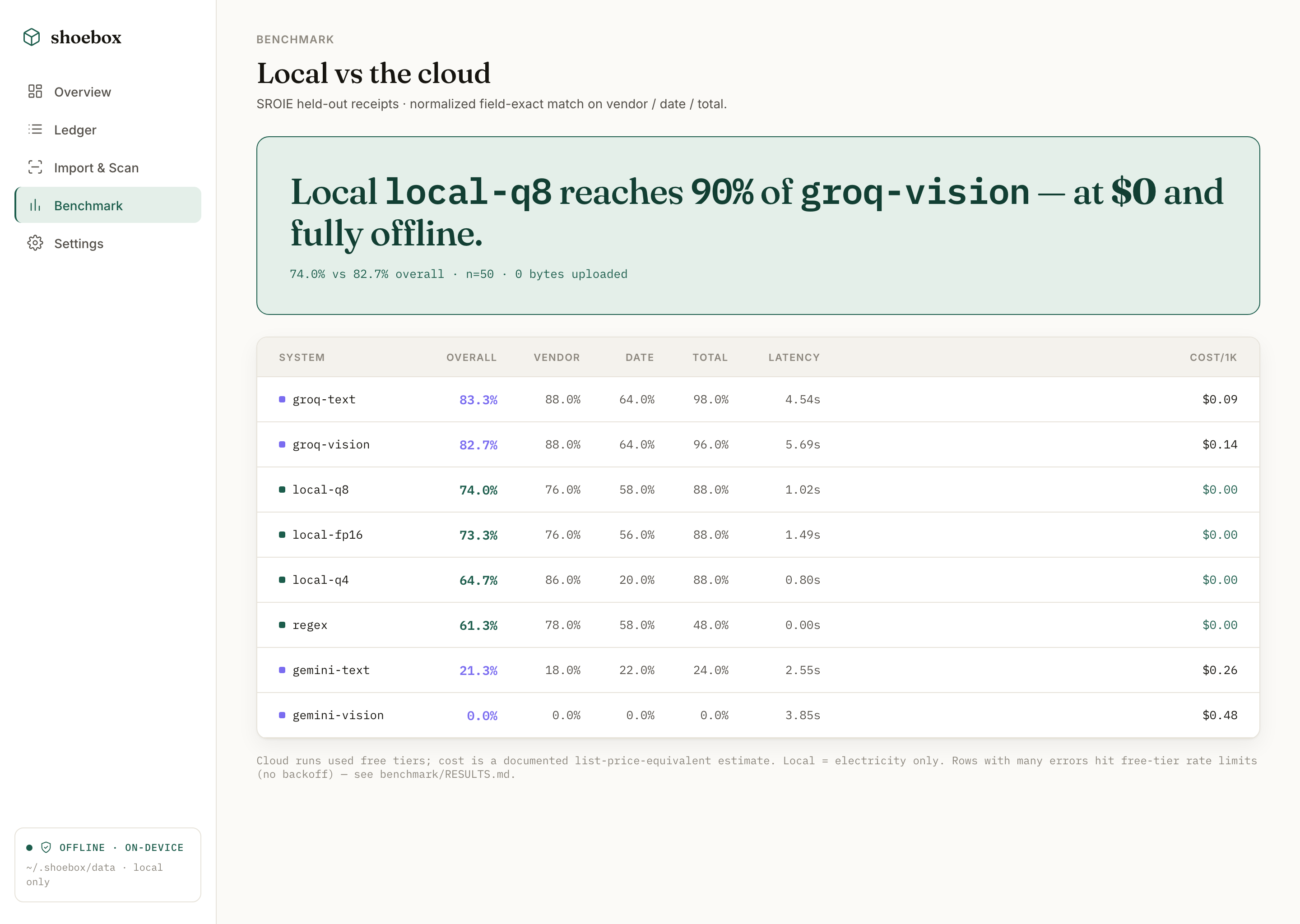
Chose to prove the privacy-vs-accuracy trade-off on a labelled set (SROIE) rather than assert it. Trade-off: building an honest eval (regex baseline, local LLM, and cloud adapters scored the same way) took longer than the pipeline, but "90% of cloud at $0" is now a number, not a slogan.
A swappable Extractor over a hardcoded model
Chose a single Extractor protocol with a regex baseline, a local Ollama adapter, and cloud adapters (Gemini, Groq) behind it. Trade-off: an extra abstraction, but the provider is a one-line swap and the cloud adapters exist only to benchmark against. They never touch your real receipts.
A QLoRA fine-tune over prompt-only extraction
Chose to fine-tune Qwen-3B with QLoRA (MLX) on receipt fields rather than lean harder on the prompt. Trade-off: a training step to maintain, but it moved local accuracy from 72% to 80% on SROIE, closing most of the gap to cloud without leaving the laptop.
The interesting result wasn't that local lost. It's how little it lost. Once the gap to frontier cloud vision was ~10 points at $0 and fully offline, "send it to someone else's server" stopped being the obvious default.
what the benchmark settled
Harder than expected
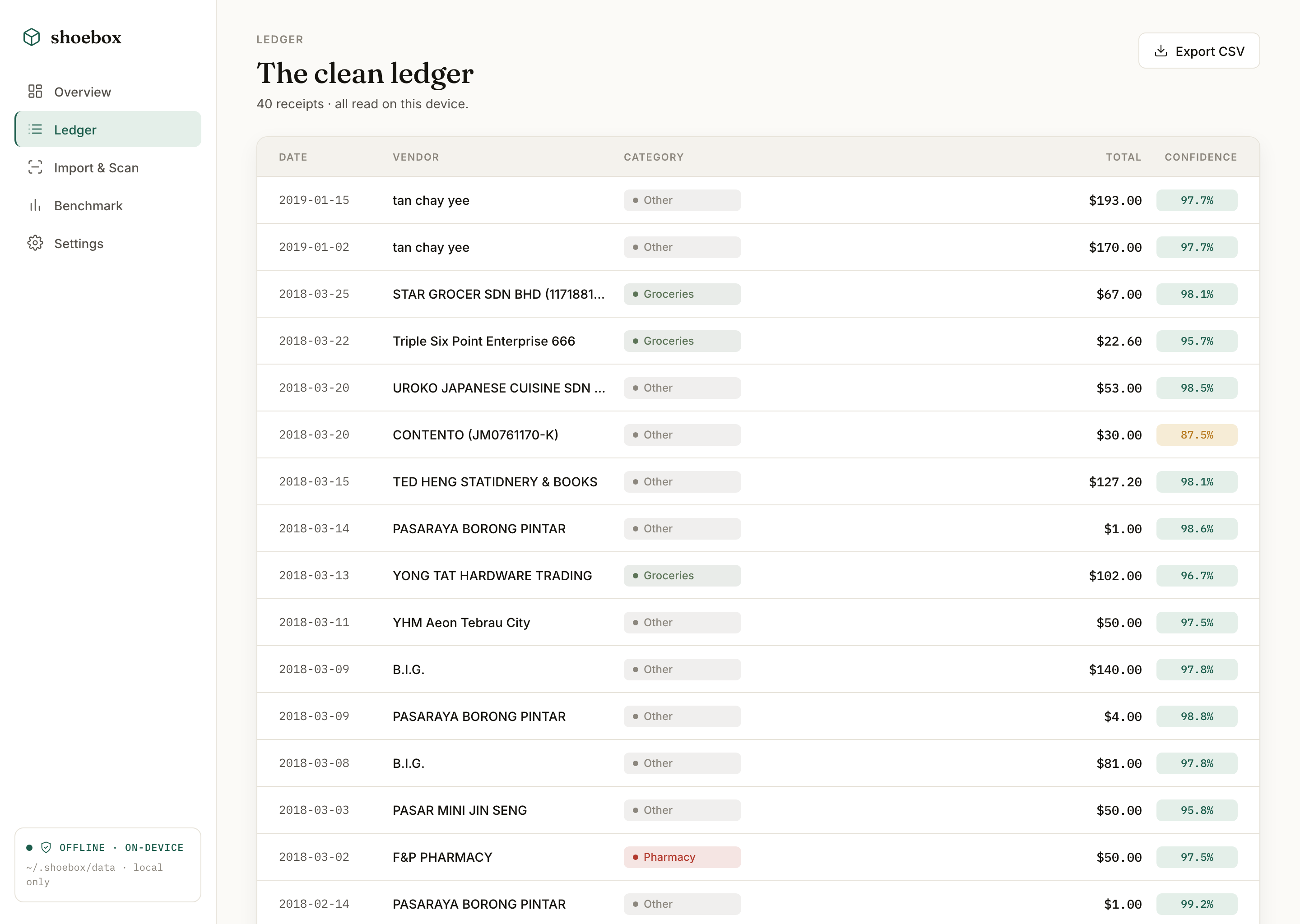
Trusting a small local model's output. A 3B model returns confident JSON that's subtly wrong: a transposed total, a hallucinated date. The fix wasn't a bigger prompt; it was a strict pydantic parse at the boundary, one repair retry, then fail, plus a per-receipt confidence score so the ledger never hides how sure it actually is.
Results
- 74% vs 82.7%: local field accuracy vs cloud frontier (SROIE)
- 72% → 80%: base vs QLoRA-tuned local model
- $0: fully offline, nothing leaves the machine
Local + source
shoebox is local-first by design. There's no hosted URL, because the whole point is that nothing leaves your laptop. The fine-tuned model is public; the code is open.