settle: AI Bill Review with a human in the loop
Claude vision reads invoices and flags anomalies against each vendor's own history, with every flag gated for human approval before payment.
TL;DR
- Claude vision reads invoices and flags anomalies against each vendor's own history.
- 55 unit + 14 e2e tests run against a real database, not mocks.
- A deliberate AI-vs-deterministic split. Full automation was the wrong call.
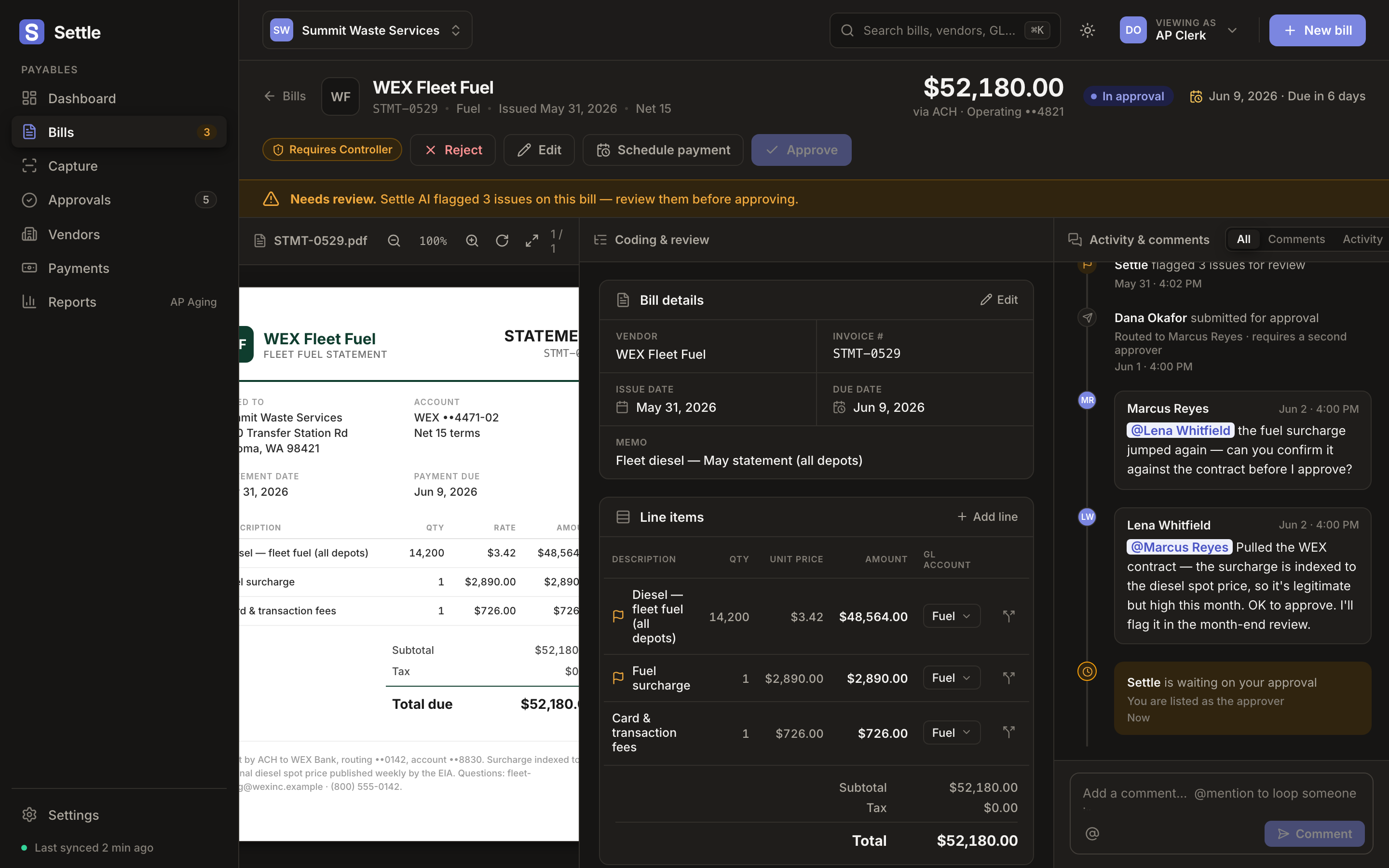
Problem
Markups hide in the line items.
AP invoices bury overcharges in fees, swapped SKUs, and quietly creeping unit prices. Reviewers skim dozens a day and approve on trust. The bad line is the one nobody reads. settle reads every line so the human only looks where it matters.
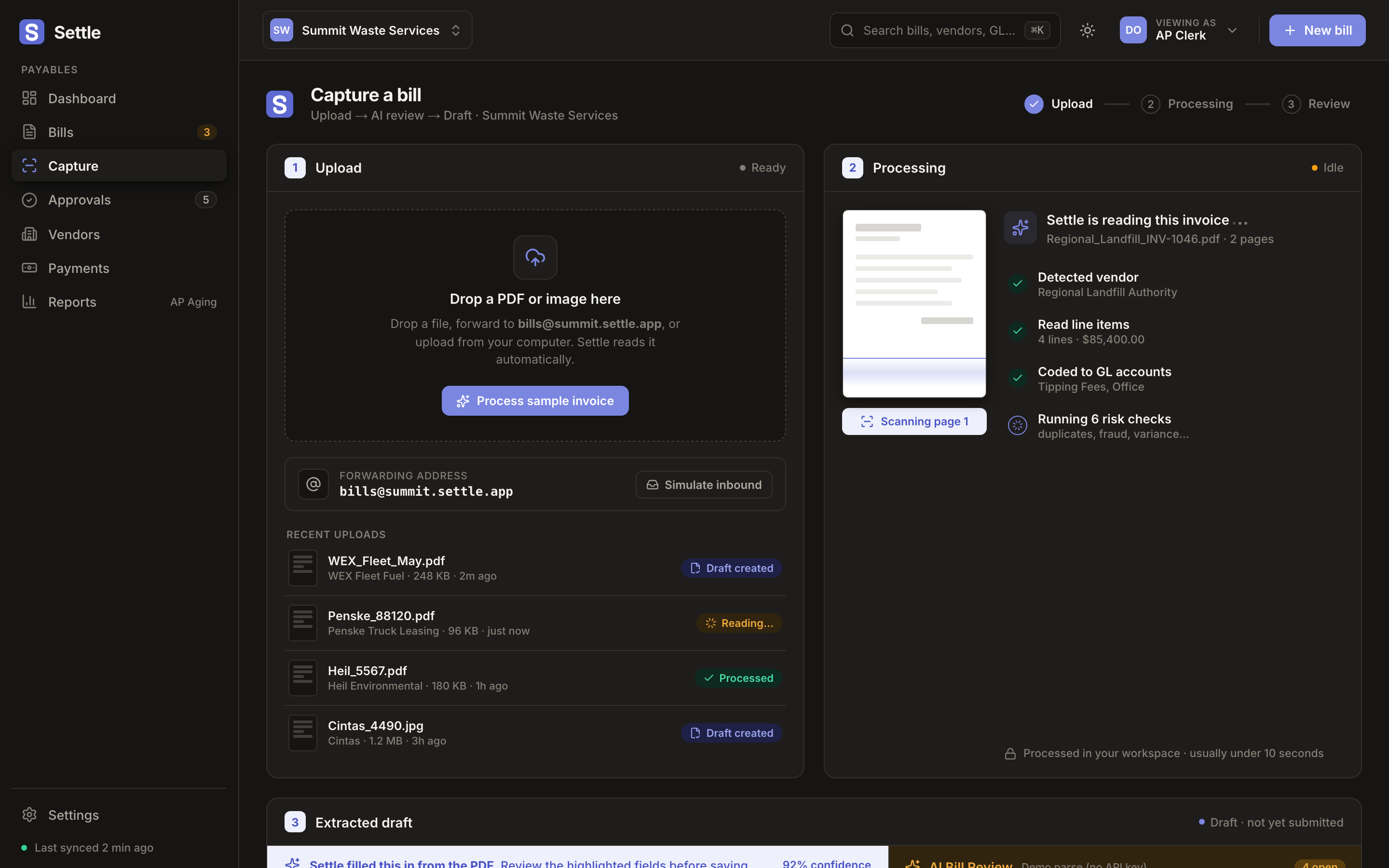
Architecture
upload → Claude vision extract → vendor-history diff → flag queue → human triage → ledger write
Key decisions
Claude vision over OCR + rules
Chose a vision model over template OCR because invoice layouts vary too much to template. Trade-off: higher per-page cost and latency, paid down with caching and batching.
Human-in-the-loop over full automation
Chose to gate flagged charges for human approval rather than auto-reject. Trade-off: lower throughput, but a single wrong auto-rejection erodes trust faster than any speed-up earns it.
Anomaly vs vendor history over static thresholds
Chose to compare each charge against the vendor's own past invoices rather than fixed dollar rules. Trade-off: needs a history warm-up before flags get sharp, but it catches drift that thresholds miss.
Real-DB tests over mocks
Chose Playwright against a real Neon branch over mocked data. Trade-off: slower CI, but it caught Drizzle migration bugs that mocks would have hidden until production.
The model's job isn't to decide. It's to make the human's decision fast. Once I optimized for triage speed instead of automated accuracy, the right architecture became obvious.
the insight that reshaped the product
Harder than expected
Getting the AI and deterministic paths to agree on one data shape. The model returns fuzzy confidence; the ledger needs exact cents. Reconciling the two, and deciding where rounding lives, took longer than the vision pipeline itself.
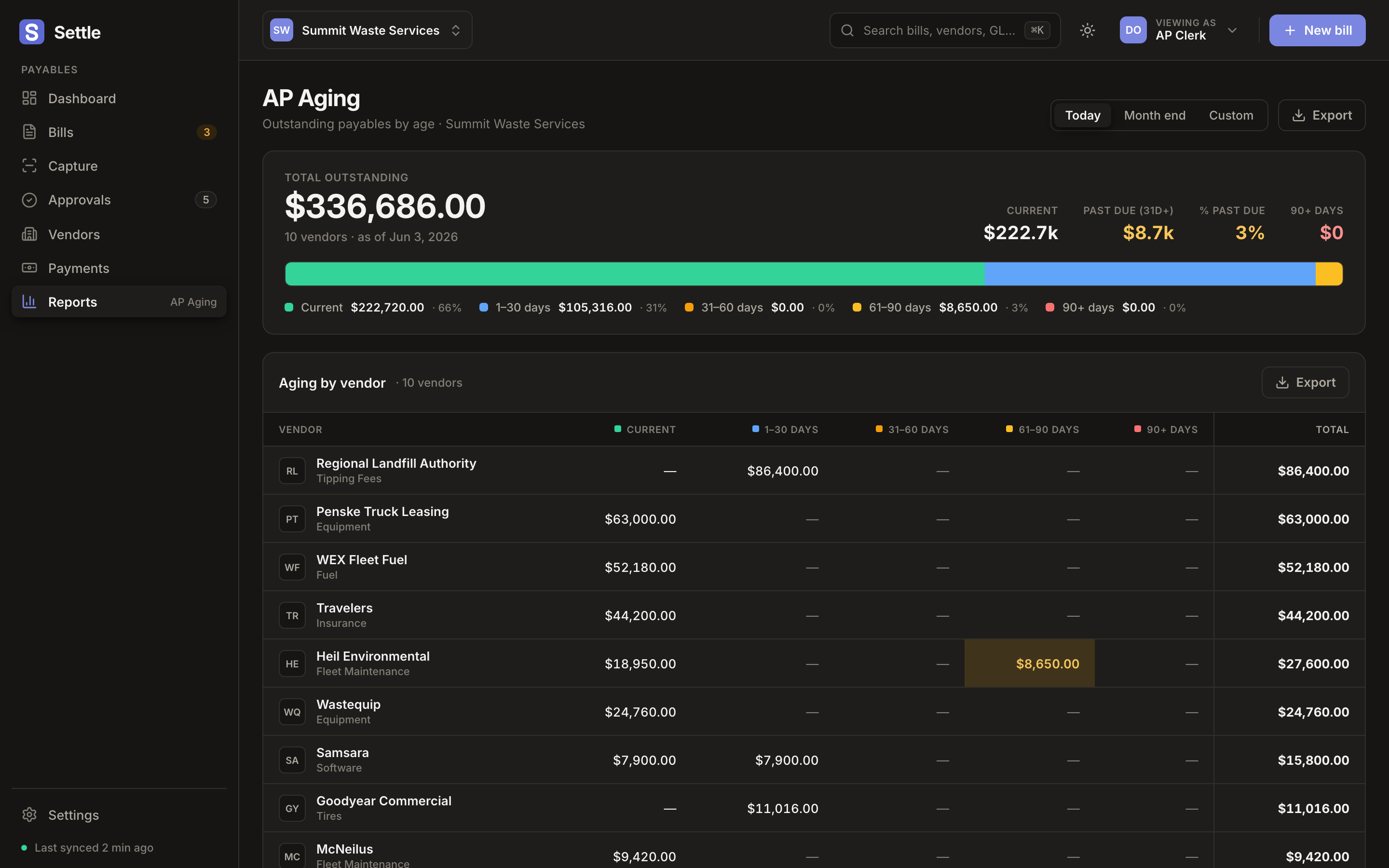
Results
- 55 + 14 unit + e2e tests, real DB
- Every flag gated for human approval before payment
- 0 auto-rejections (humans decide)
Live + source
The live demo runs on seeded data with a role switcher, no login. Walk the flow: capture → flag triage → cockpit.