rubric: CI for prompts
Treats prompts and agents like code: golden sets, deterministic scorers, an LLM-as-judge calibrated against human labels (Cohen's κ 0.81), and a gate that fails the PR when a prompt change quietly makes the output worse.
TL;DR
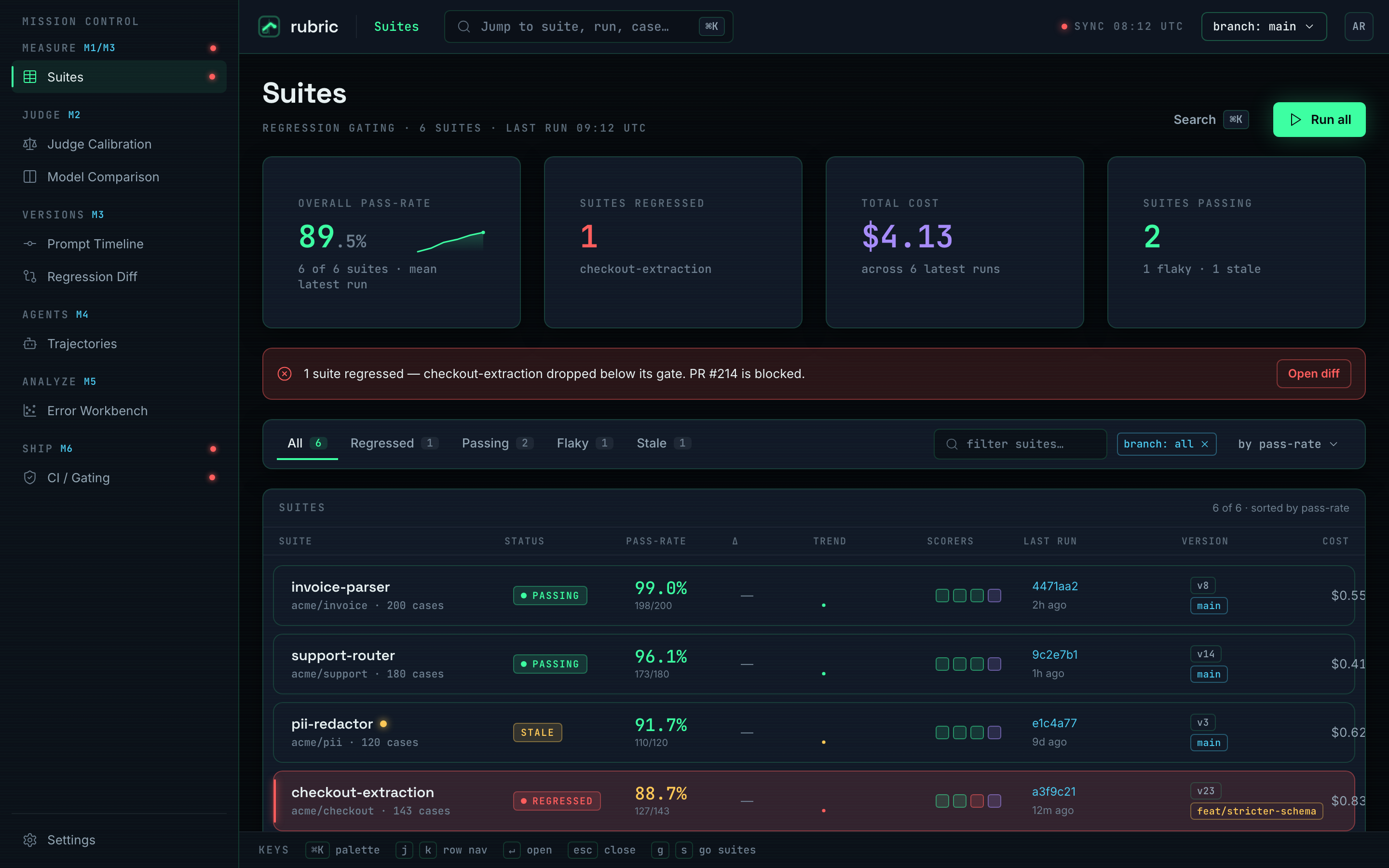
- A test suite for prompts and agents: golden sets, scored every run, diffed against the last green run, gating the PR on regressions.
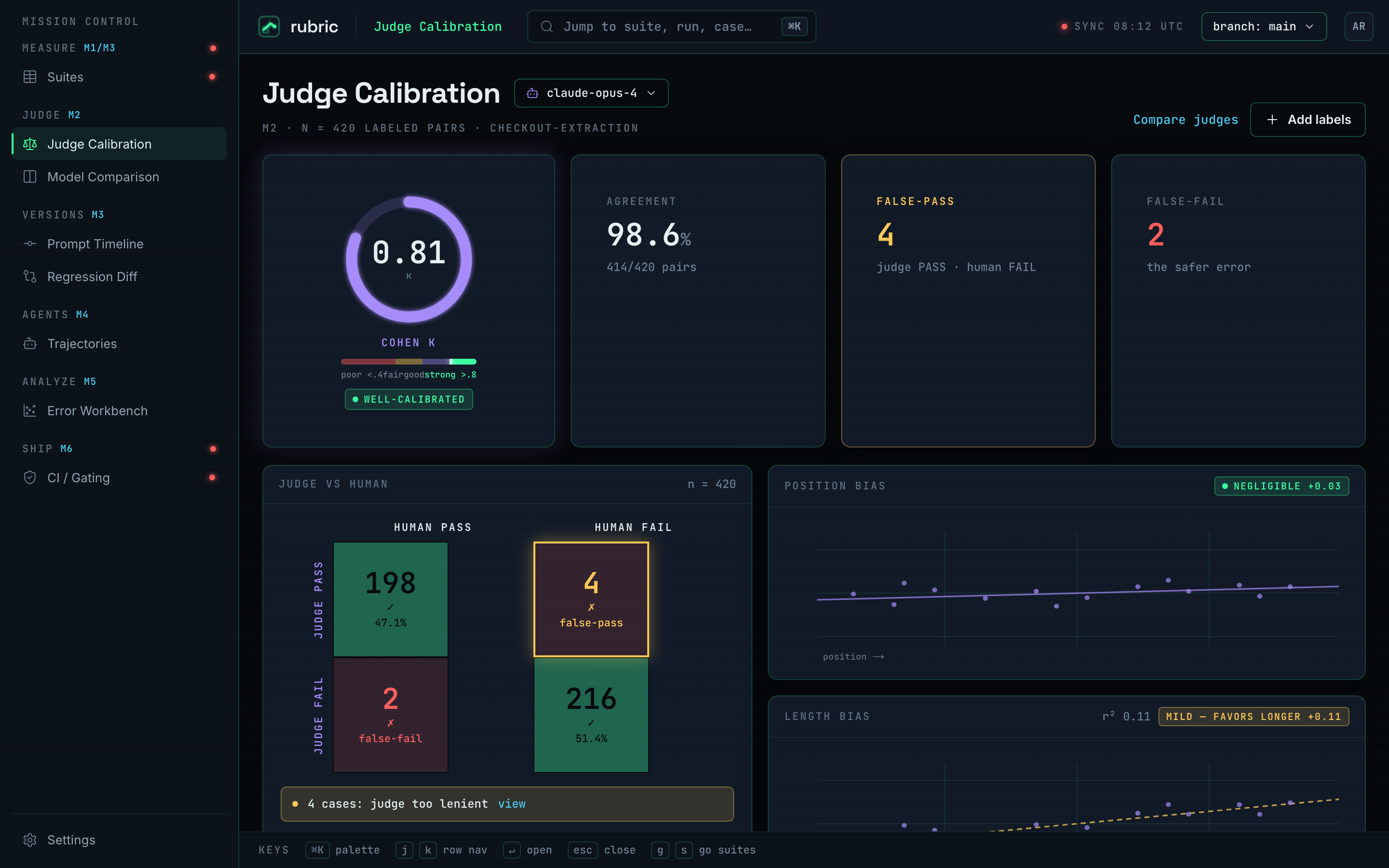
- An LLM-as-judge calibrated against human labels (Cohen's κ 0.81, a judge-vs-human confusion matrix, position/length-bias checks) so the judge is a measured instrument, not a black box.
- Born from an audit of two shipped products that found the same gap: prompts changed by vibes, quality measured by hope.
Problem
You can't ship what you can't measure.
A test suite stops you shipping a regression in logic. Nothing stops you shipping a regression in quality: a reworded system prompt that quietly drops accuracy, a model swap that tanks faithfulness, an agent that starts picking the wrong tool. I'd seen exactly this in two shipped products: a hardcoded confidence number standing in for a measurement that never existed. rubric closes that gap.
Architecture
CLI ───── writes ─────► libSQL store ◄───── reads ───── Next.js dashboard
(bin/rubric.ts) (SQLite / Turso) (server components)
├─ spec golden-set YAML → zod
├─ scorers exact · json-schema · field-accuracy · judge
├─ runner fixture (offline) · exec (any language, JSON stdout)
└─ calibration Cohen's κ · confusion matrix · bias regression
The CLI is the product; the dashboard is a read-only lens over what it writes. The two surfaces meet only at the store.
Key decisions
Deterministic scorers first, the judge only when needed
Chose exact-match, JSON-schema, and field-accuracy with a pass floor as the default (no model call, no flake, no cost) and reached for the LLM judge only where the criterion is genuinely subjective. Trade-off: less coverage of open-ended outputs by default, but the gate is fast, free, and never flaky.
A calibrated judge over a trusted one
Chose to measure the judge against human labels rather than assume it agrees with me. Trade-off: a labelling step (rubric label), but it surfaces the dangerous leniency bias (the false-pass) and turns "the judge said it's fine" into a number you can defend.
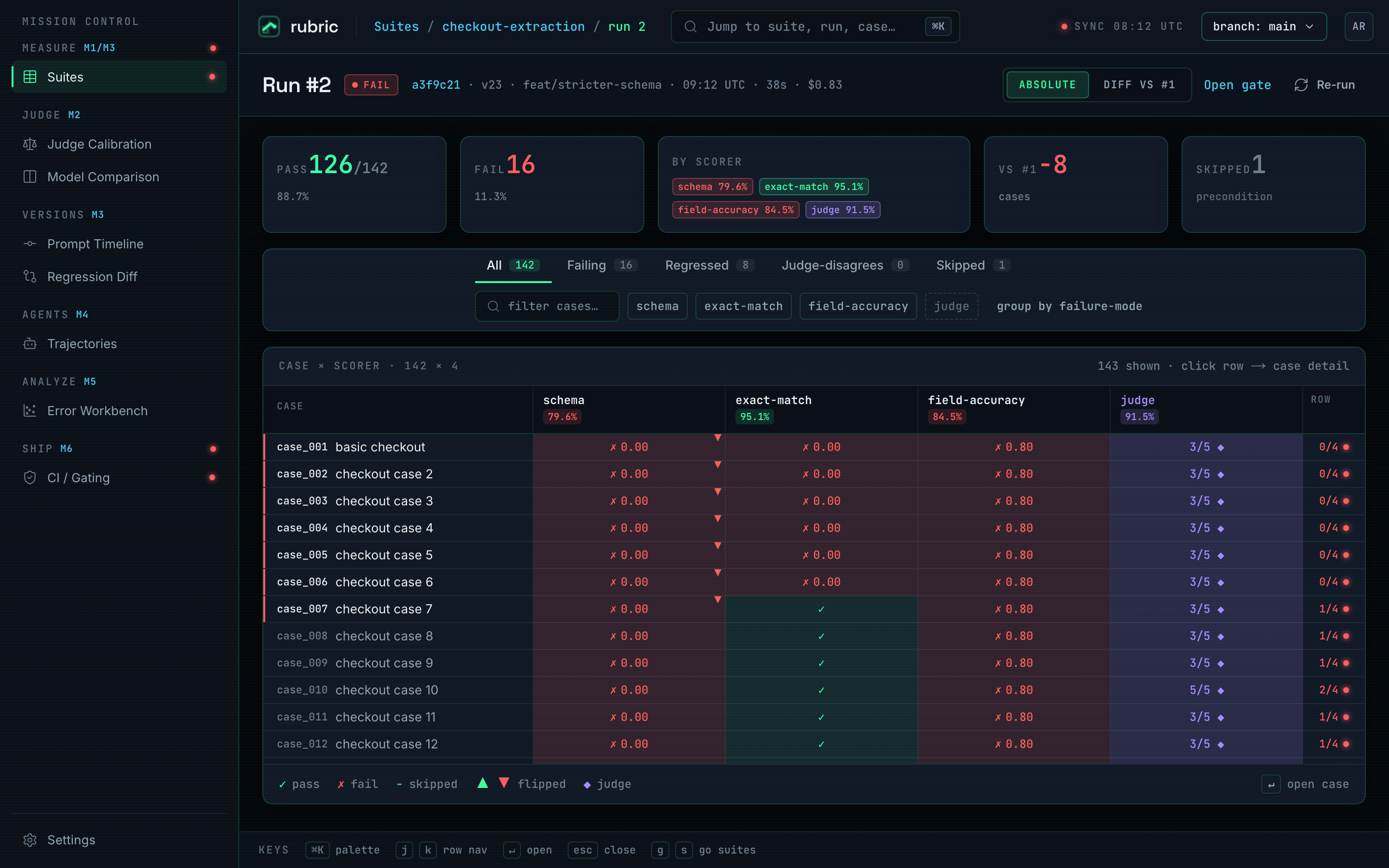
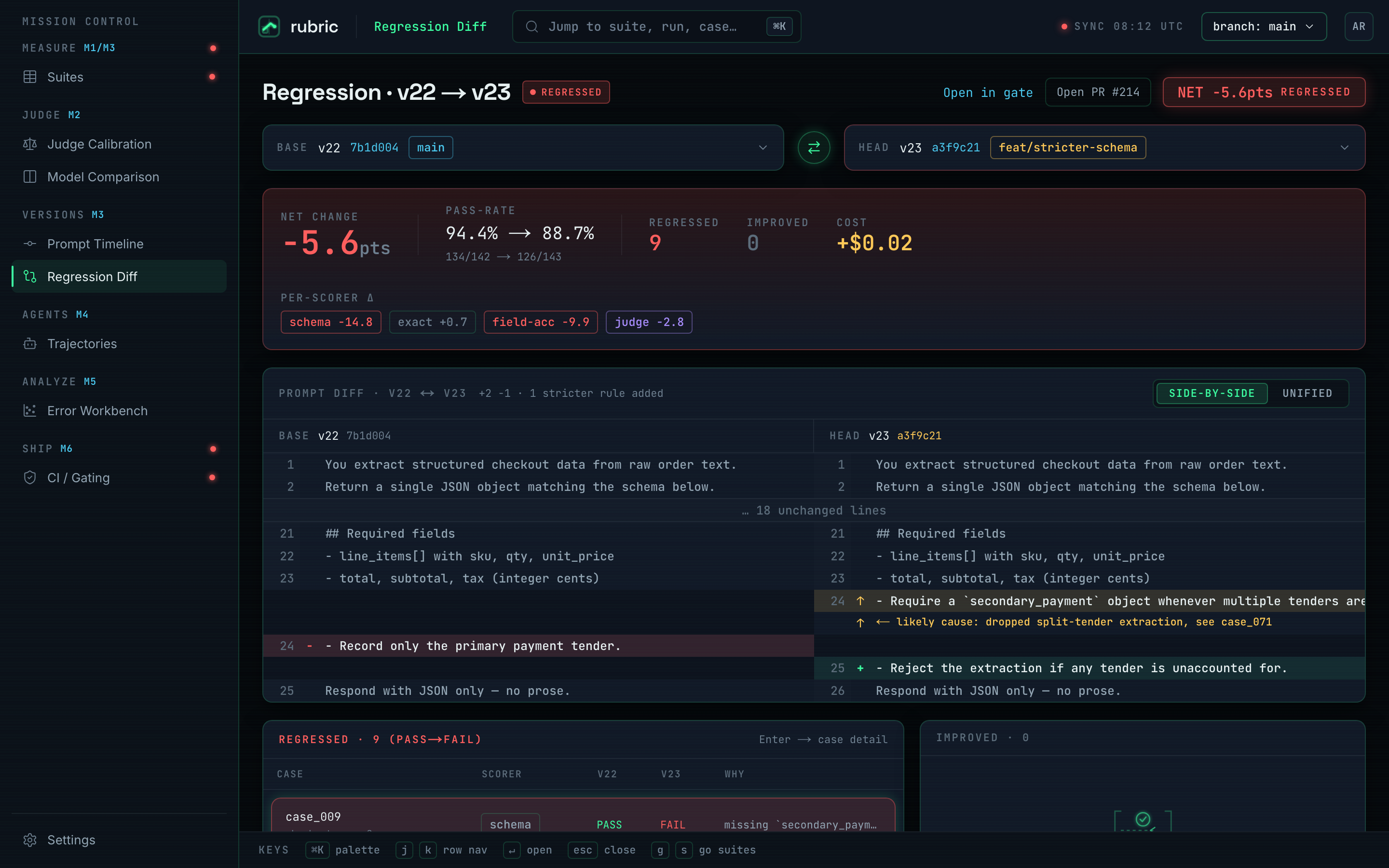
Gate on a diff, not a score
Chose to persist every run and diff it against the last green run for the same suite + prompt version, exiting non-zero past a metric's floor. Trade-off: you need a baseline before the gate means anything, but it shows cause and effect: the prompt diff beside the cases that flipped pass→fail.
A judge you haven't calibrated is just a second opinion you've decided to trust. The κ and the confusion matrix are what make it evidence. The false-pass count is the number that actually matters.
why calibration is non-negotiable
Harder than expected
Making the judge trustworthy enough to gate a PR. An uncalibrated LLM judge is confidently lenient: it passes things a human would fail, and those false-passes are exactly the regressions you're trying to catch. Most of the work went into the calibration math and the labelling flow, not the judging itself.
Results
- κ 0.81: judge-vs-human agreement, calibrated
- 126/142: passing on the demo suite, one regression caught
- Red PR: the gate blocks the merge, not just logs it
Live + source
The dashboard runs on a pre-reconciled demo dataset, so every screen is explorable without an API key. The deterministic scorers run fully offline; the judge is swappable (Groq, or Ollama for fully local).