hiring-radar: Hybrid search that doubles recall
Hybrid retrieval (semantic + keyword, fused with RRF) lifts recall@10 to 0.52, nearly double semantic alone, with a reproducible gold set committed to the repo.
TL;DR
- Hybrid retrieval (semantic + keyword, fused with RRF) lifts recall@10 to 0.52, nearly double semantic alone at 0.28.
- MRR 0.74 vs 0.28 semantic vs 0.16 exact, measured on a committed gold set, so it's reproducible.
- Beyond search: an agentic matcher with a bounded tool-use loop, run-to-run memory, and an MCP server.
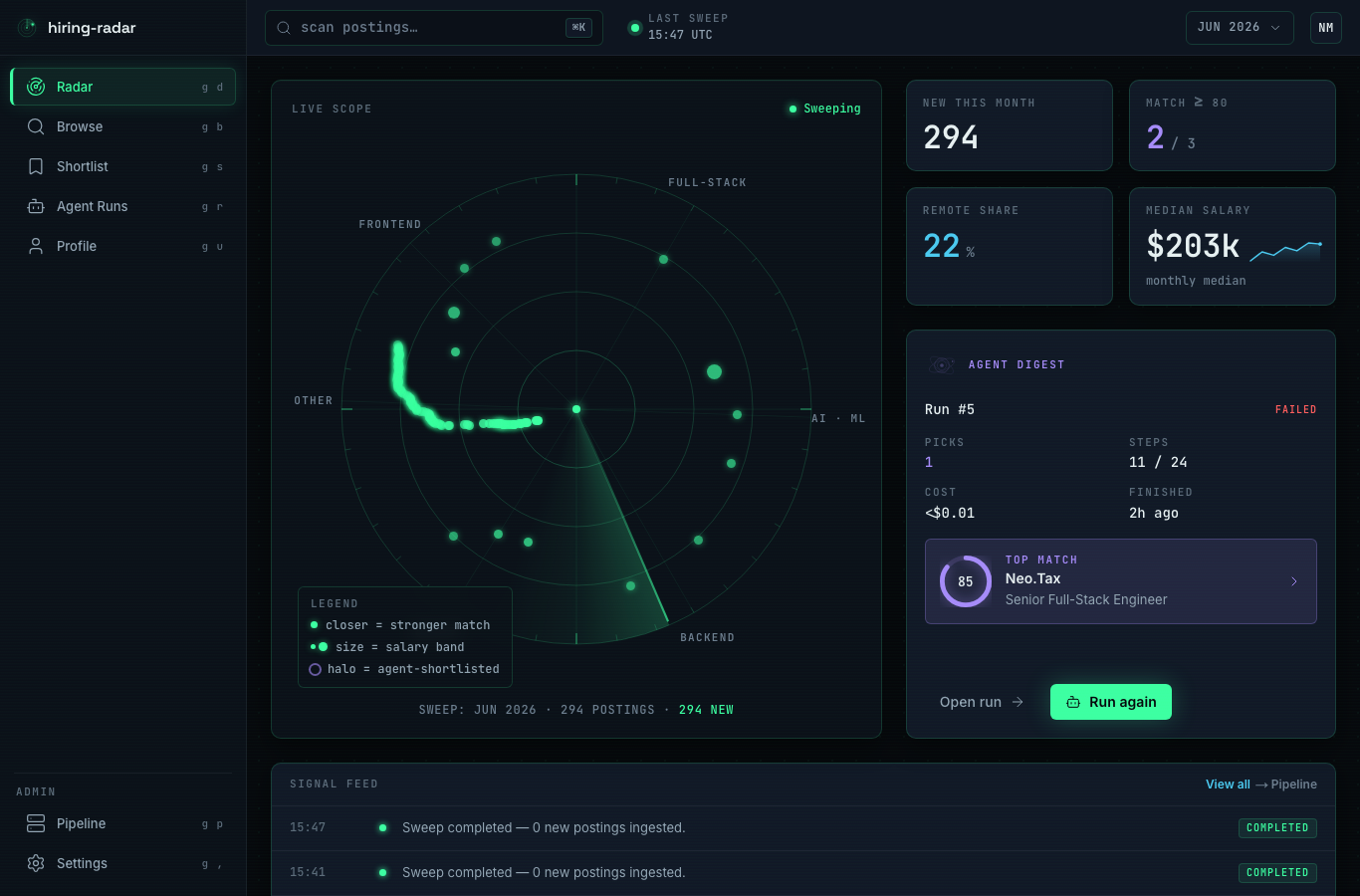
Problem
Neither search alone finds the job.
Ranking HN "Who is hiring" postings is a recall problem. Semantic search grasps intent but misses exact terms: company names, framework versions, locations. Keyword search nails those but ignores meaning. Either alone leaves half the right postings off the first page.
Architecture
ingest HN thread → LLM-extract fields → chunk + local embed → pgvector HNSW + tsvector → RRF fusion → ranked results
Browse the whole corpus by exact, semantic, or hybrid. The mode toggle is the thesis in one control:
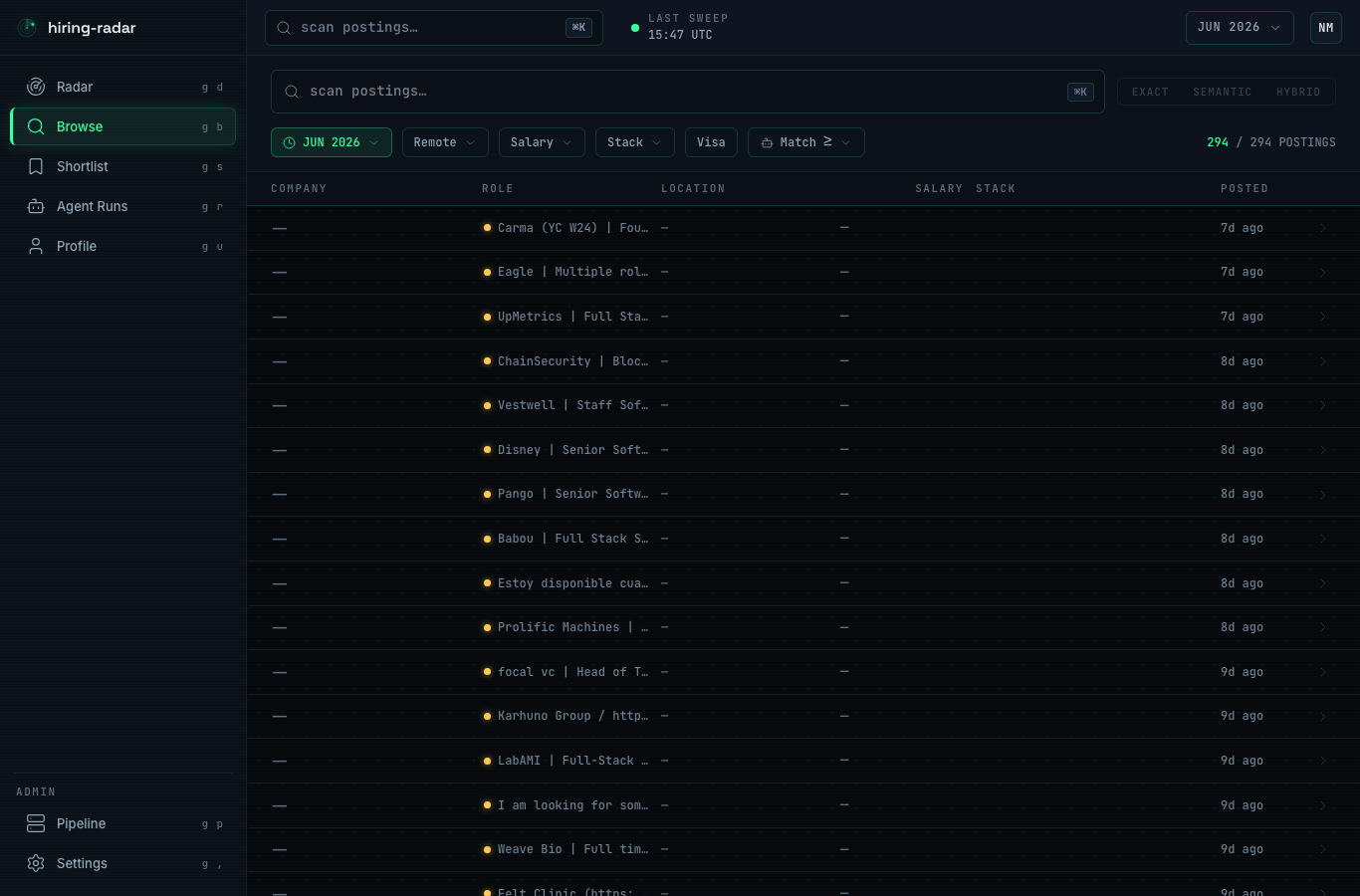
Key decisions
pgvector HNSW over exact scan
Chose an approximate HNSW index over an exact cosine scan. Trade-off: a sliver of recall for a large latency win, and recall is recovered by the keyword leg of the hybrid anyway.
RRF fusion over weighted score blending
Chose reciprocal rank fusion over tuning a weighted blend of raw scores. Trade-off: discards score magnitude, but it's robust and needs no per-query tuning across two very different scales.
A hand-built gold set over synthetic labels
Chose to label a gold set by hand rather than generate relevance judgements with a model. Trade-off, and a real limitation: it's small and single-annotator, so the numbers are directional, not absolute.
Hybrid didn't just edge out the best single method. It beat both on every query class. The two retrievers fail on different inputs, so fusing them covers each other's blind spots.
what the eval proved
Results
Measured on a hand-labelled gold set (12 queries · 294 postings), committed alongside the eval script:
mode recall@10 MRR avg latency
exact (keyword) 0.140 0.156 ~199 ms
semantic (vector) 0.276 0.283 ~351 ms
hybrid (RRF) 0.521 0.737 ~348 ms
Hybrid roughly doubles semantic recall and lifts MRR to 0.74. RRF recovers the literal term hits (a "Rust" or "Kubernetes") that pure vectors miss, while keeping the semantic matches that keyword can't reach.
Beyond search: a matching agent
A bounded tool-use loop ranks postings against your profile: it calls search_jobs, read_posting, and recall_memory (it remembers verdicts from past runs), shortlists, and stops the instant it trips a hard cap (24 steps, 600k tokens, or $1.00), checked before every model call. Untrusted posting text is spotlighted as data, never instructions. The same tools ship as an MCP server, callable from Claude.
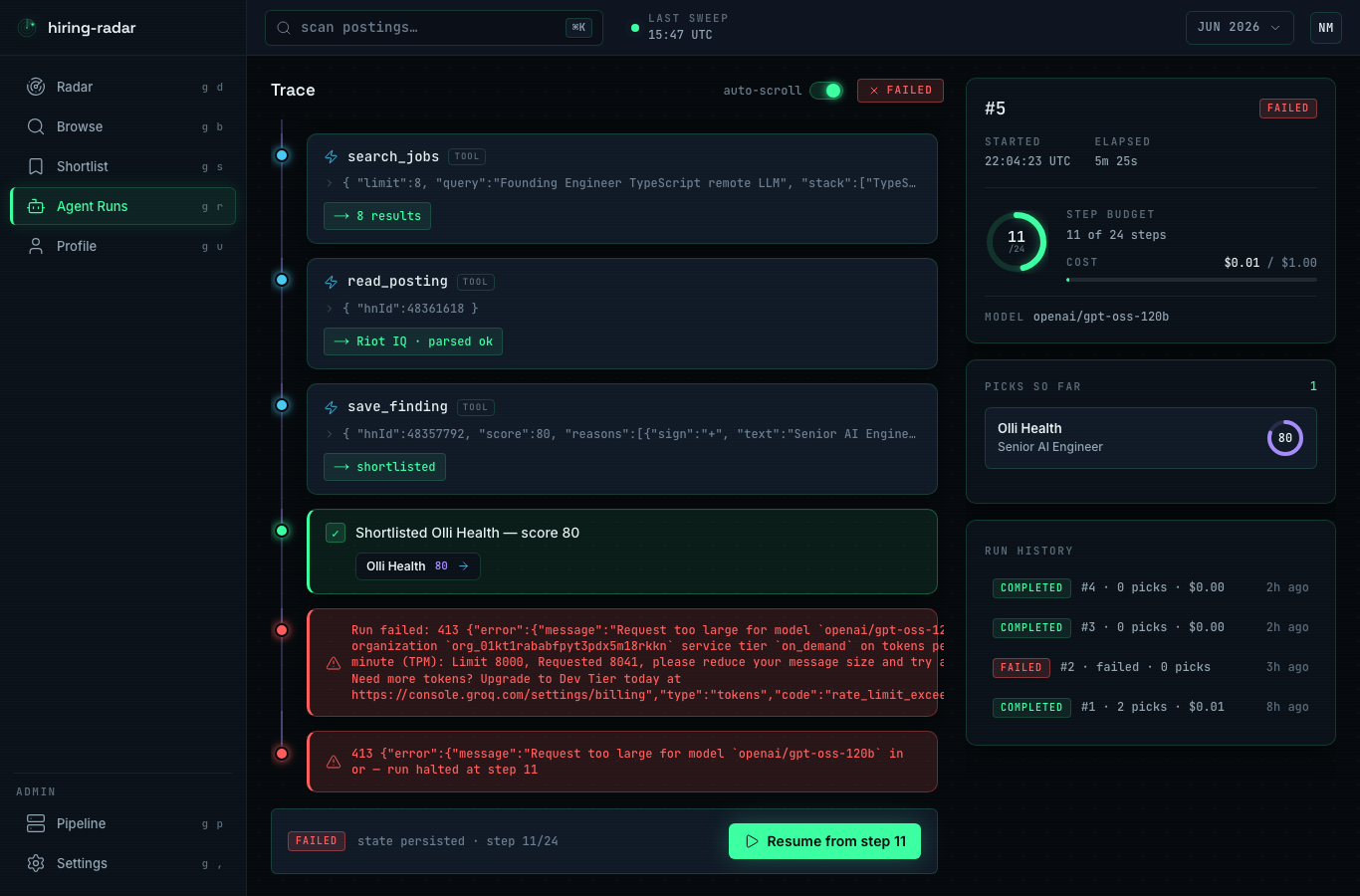
Harder than expected
Building an eval I could trust. With a small, single-annotator gold set, every metric carries a confidence interval wide enough to mislead. Stating that limitation honestly, and treating the numbers as directional, mattered more than chasing a higher score.